十分钟掌握Seaborn,进阶Python数据可视化分析¶
为什么用 Seaborn¶
Seaborn 是基于 Python 且非常受欢迎的图形可视化库,在 Matplotlib 的基础上,进行了更高级的封装,使得作图更加方便快捷。即便是没有什么基础的人,也能通过极简的代码,做出具有分析价值而又十分美观的图形。
Seaborn 可以实现 Python 环境下的绝大部分探索性分析的任务,图形化的表达帮助你对数据进行分析,而且对 Python 的其他库(比如 Numpy/Pandas/Scipy)有很好的支持。
那么现在开始,十分钟的时间,你就可以了解 Seaborn 中常用图形的绘制方法,以及进阶的可视化分析技巧。
Seaborn 绘图上手¶
如果你还没有安装 Python 环境,那么推荐你安装 Anaconda,对于上手 Python 来说更加简单,不容易出差错。Anaconda 的安装教程网上很多,找到对应版本客户端安装即可。
安装好后,即可在终端(cmd)安装核心库 Seaborn 和 Matplotlib。
安装 Matplotlib
python -m pip install matplotlib
安装 Seaborn
pip install seaborn
然后打开 Jupyter Notebook(安装好 Anaconda 后,Jupyter 也已装好,在应用窗口中可以找到),我们就可以直接上手了。
先来一段基本的代码:
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
sns.set(style="darkgrid")
sns.set(rc={'figure.figsize':(11.7,8.27)})
titanic=sns.load_dataset('titanic')
sns.barplot(x='class',y='survived',data=titanic)
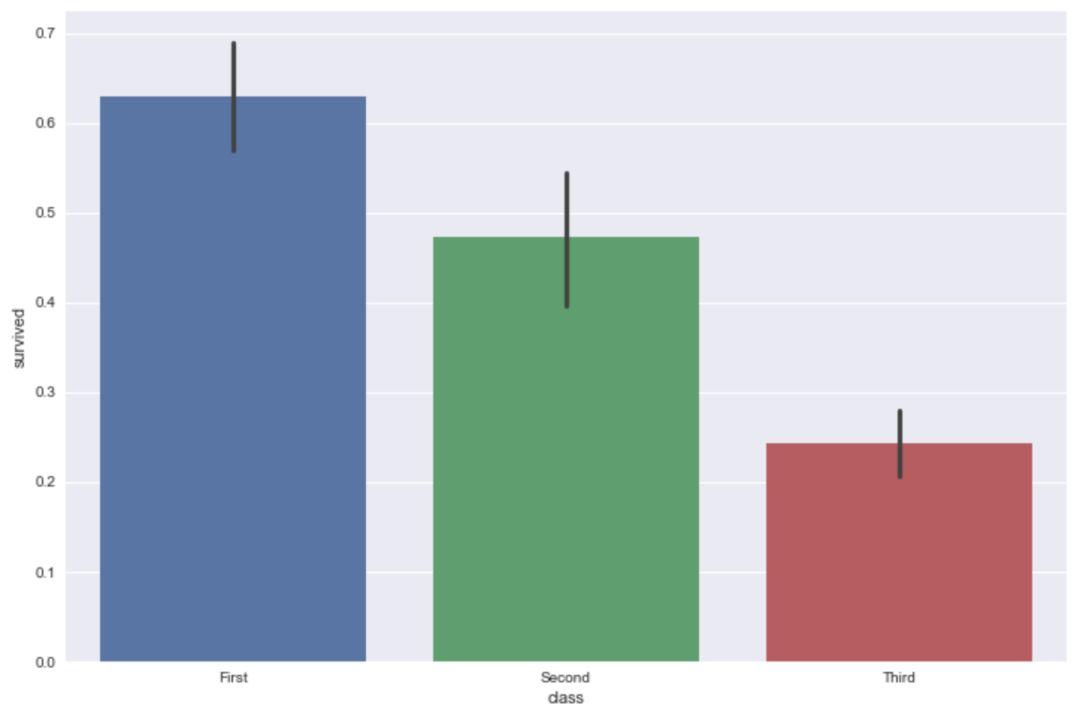
通过以上代码,我们就绘制出了基本的条形图,是不是超级简单。这也是用 Seaborn 实现一个图形的基本模式,接下来我们把上面的代码拆开来看。
1.导入绘图模块
import seaborn as sns
import matplotlib.pyplot as plt
这里我们导入 Seaborn 和 Matplotlib.pyplot 模块,分别命名为 sns 和 plt,原则上这个简称是可以随意写的,但为了规范,尽量写成这样。这里引入 Matplotlib.pyplot ,是为了通过 Matplotlib 的参数去进行更好的控制。
2.提供显示条件
%matplotlib inline
这里的 %matplot inline 是为了在 Jupyter 中正常显示图形,若没有这行代码,图形显示不出来的。
3.导入数据
titanic=sns.load_dataset('titanic')
这里我们用 Seaborn 的 load_dataset() 方法导入数据 ‘titanic’,这是泰坦尼克号的相关数据,内置于 Seaborn(内置数据都可以用此方法导入)。当然 Seaborn 还提供了其他的内置数据,以下是目前内置的数据集:
- anscombe
- attention
- brain_networks
- car_crashes
- diamonds
- dots
- exercise
- flights
- fmri
- gammas
- iris
- mpg
- planets
- tips
- titantic
地址:https://github.com/mwaskom/seaborn-data
4.输出图形
sns.barplot(x='class',y='survived',data=titanic)
这是图形输出的直接代码,barplot 表示输出条形图,常用的有:
- countplot
- boxplot
- violinplot
- regplot
- lmplot
- heatmap
后面详细介绍
barplot() 括号里的是需要设置的具体参数,涉及到数据、颜色、坐标轴、以及具体图形的一些控制变量,一般比较固定的是 x、y、data,分别表示x轴,y轴,以及选择的数据集。
Seaborn 图形可视化¶
distplot 直方图¶
通常我们在分析一组数据时,首先要看的就是变量的分布规律,而直方图则提供了简单快速的方式,在 Seaborn 中可以用 distplot() 实现。
我们首先导入数据集 'titanic',并查看随机的10行数据,对数据集有一个初步的印象:
import matplotlib.pyplot as plt
import seaborn as sns
%matplotlib inline
#导数数据集'titanic'
titanic=sns.load_dataset('titanic')
#查看数据集的随机10行数据,用sample方法
titanic.sample(10)
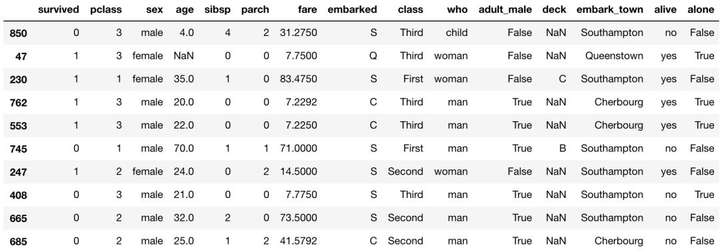
通过观察数据,我们对'age'进行直方图展示。但在绘图之前,我们观测到'age'字段中存在缺失值,需要先用 dropna() 方法删掉存在缺失值的数据,否则无法绘制出图形。
#去除'age'中的缺失值,distplot不能处理缺失数据
age1=titanic['age'].dropna()
sns.distplot(age1)
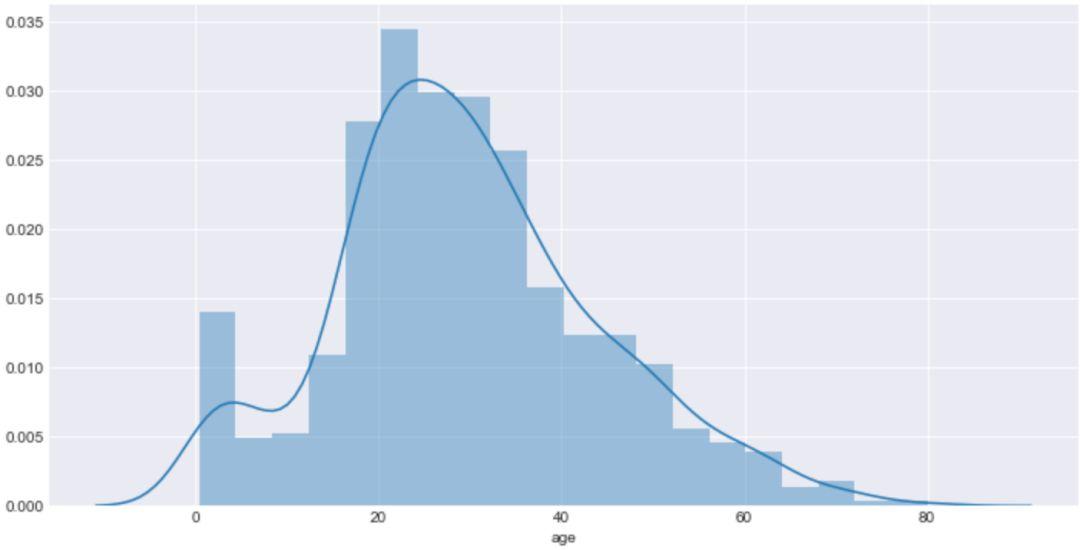
在上图中,矩形表示在不同年龄段的数量分布,并且 distplot() 默认拟合出了密度曲线,可以看出分布的变化规律。
同时我们可以调节其中的一些参数,来控制输出的图形。
kde 是控制密度估计曲线的参数,默认为 True,不设置会默认显示,如果我们将其设为 False,则不显示密度曲线。
#去掉拟合的密度估计曲线,kde参数设为False
sns.distplot(age1,kde=False)
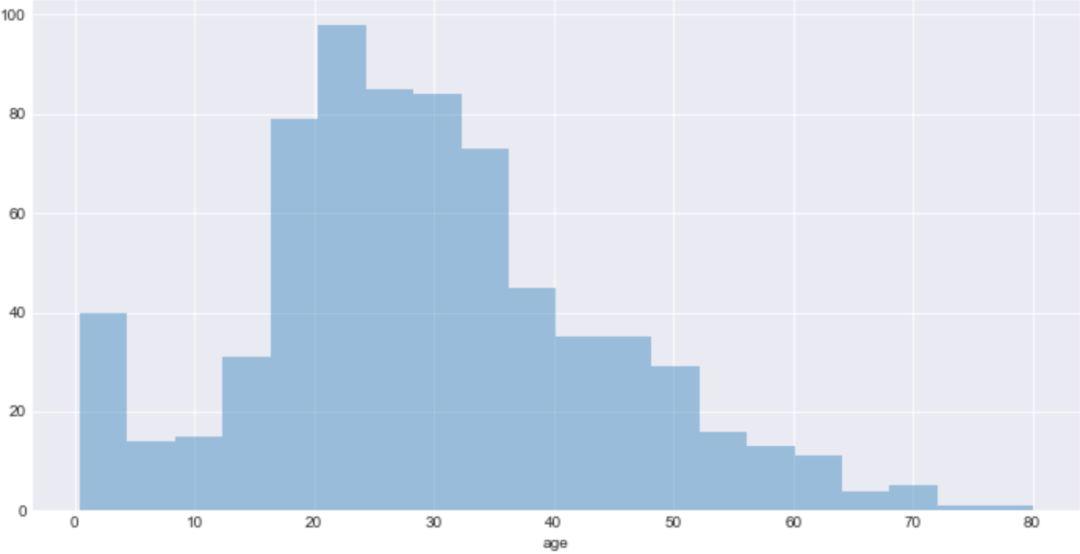
bins 是控制分布矩形数量的参数,通常我们可以增加其数量,来看到更为丰富的信息。
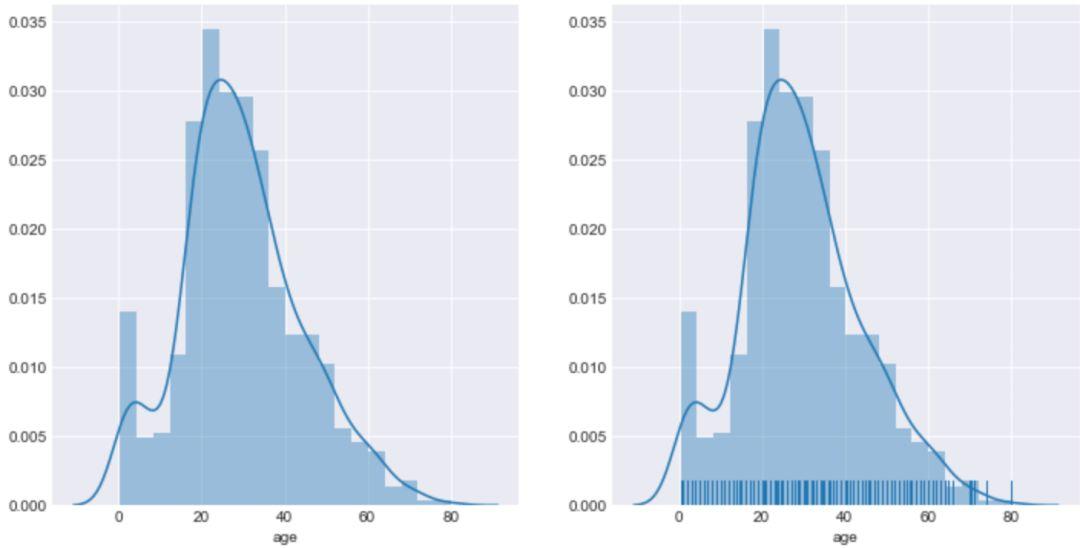
rug 参数用于控制直方图中的边际毛毯,通过控制 rug 是实现毛毯是否显示。
#创建一个一行2列的画布,主要方便对比
fig,axes=plt.subplots(1,2)
#设置'rug'参数,加上观测数值的边际毛毯
#需要用axes[]表示是第几张图,从0开始
sns.distplot(age1,ax=axes[0]) #左图
sns.distplot(age1,rug=True,ax=axes[1]) #右图
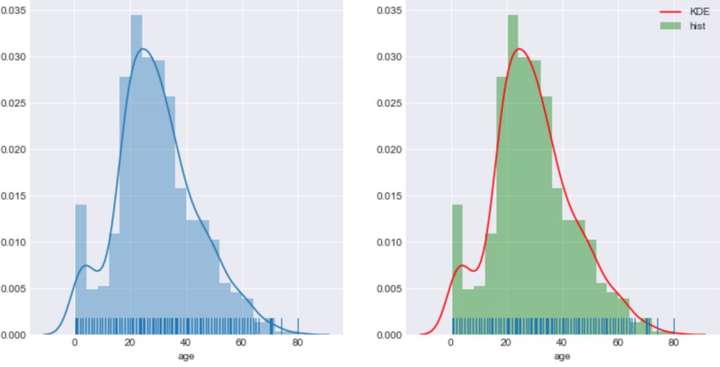
当然,除了控制矩形分布、密度曲线及边际毛毯是否显示,还可以通过更丰富的参数控制他们展示的细节,这些通过参数 hist_kws 、kde_kws 、rug_kws 来进行设置,因为其中涉及到多个参数,参数间用逗号隔开,参数外面用大括号括住。
#可以分别控制直方图、密度图的关键参数
fig,axes=plt.subplots(1,2)
sns.distplot(age1,rug=True,ax=axes[0])
sns.distplot(age1,rug=True,
hist_kws={'color':'green','label':'hist'},
kde_kws={'color':'red','label':'KDE'},
ax=axes[1])
barplot 条形图¶
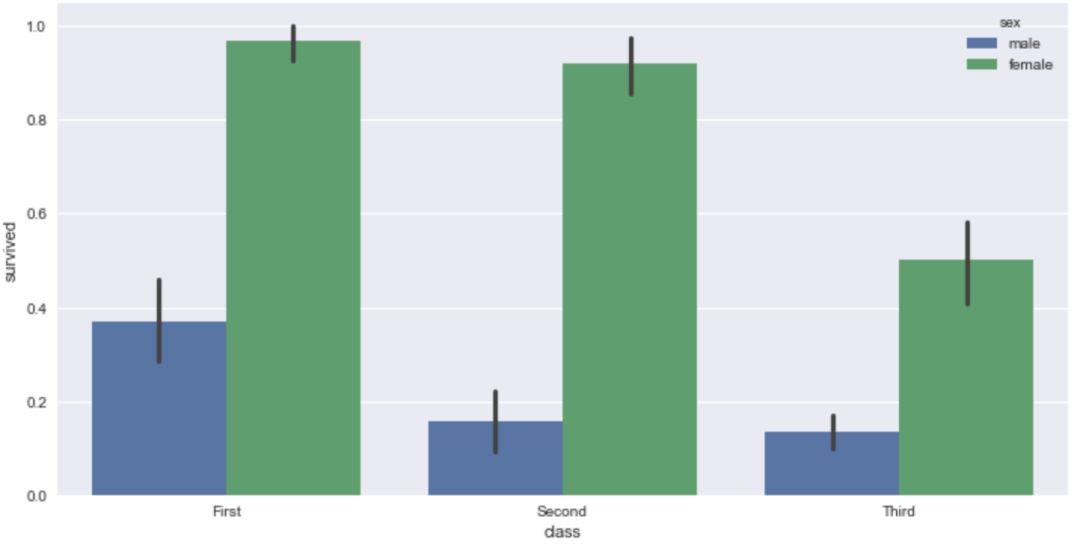
barplot() 利用矩阵条的高度反映数值变量的集中趋势,以及使用 errorbar 功能(差棒图)来估计变量之间的差值统计(置信区间)。
需要提醒的是 barplot() 默认展示的是某种变量分布的平均值(可通过参数修改为 max、median 等)。
这里我们仍然以'titanic'数据集作为展示,将'class'设为x轴,'survived'设为y轴。
#将'class'设为x轴,'survived'为y轴,传入'titanic'数据
sns.barplot(x='class',y='survived',data=titanic)

我们可以通过设置'hue'参数,对x轴的数据进行细分,细分的条件就是'hue'的参数值,比如这里我们的x轴是'class'(仓位等级),我们将其按'sex'(性别)再进行细分。
python
sns.barplot(x='class',y='survived',hue='sex',data=titanic)
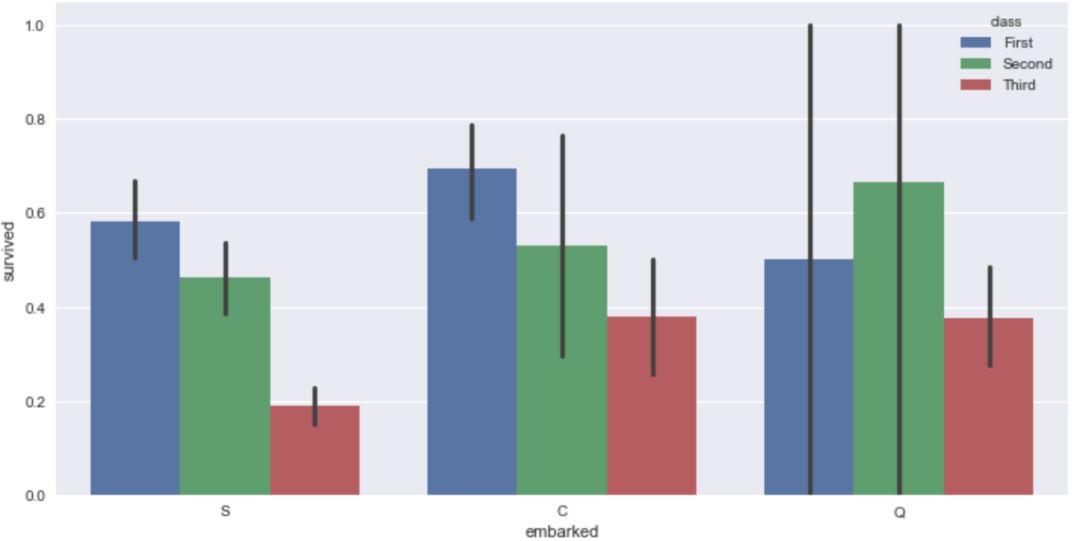
换一组数据试试,将x轴设为'embarked',y轴设为'survived',并用'class'进行细分。
sns.barplot(x='embarked',y='survived',
hue='class',data=titanic)
countplot 计数图¶
countplot 顾名思义,计数图,可将它认为一种应用到分类变量的直方图,也可认为它是用以比较类别间计数差。当你想要显示每个类别中的具体观察数量时,countplot 很容易实现,比较类似我们在 Excel 等软件中应用的条形图。
同样,我们以数据集'titanic'为例子,首先探索'deck'字段下的类别计数。
sns.countplot(x='deck',data=titanic)
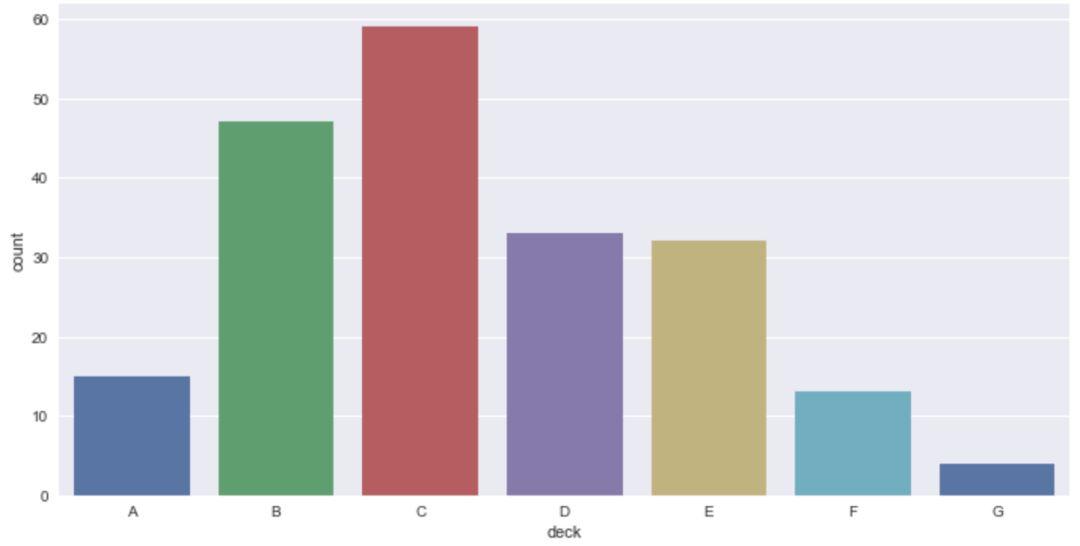
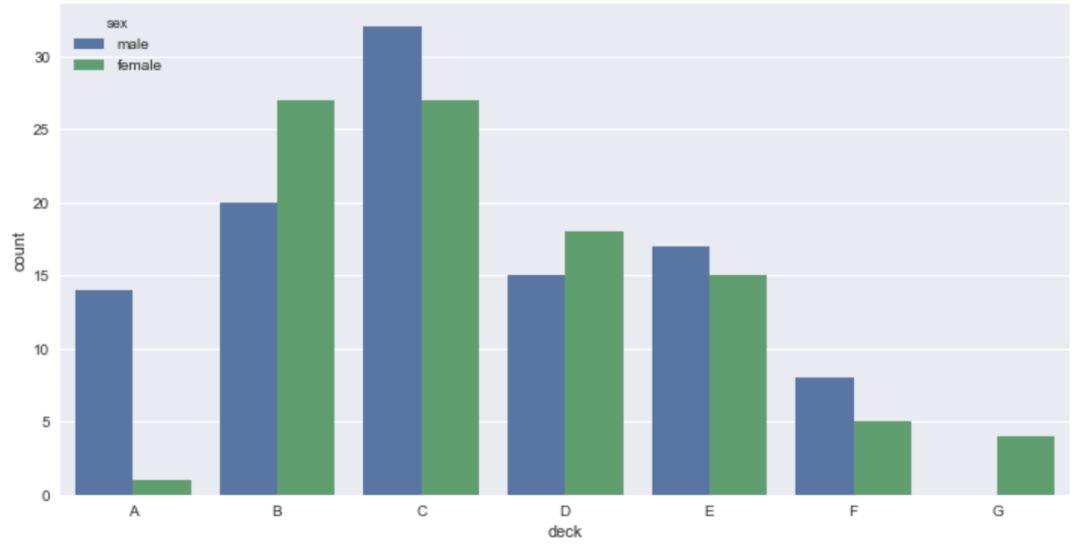
由此可见,我们选定某个字段,countplot() 会自动帮我们统计该字段下各类别的数目。当然,我们也可以再传入'hue'参数,进行细分,这里我们加入'sex'分类。
sns.countplot(x='deck',hue='sex',data=titanic)
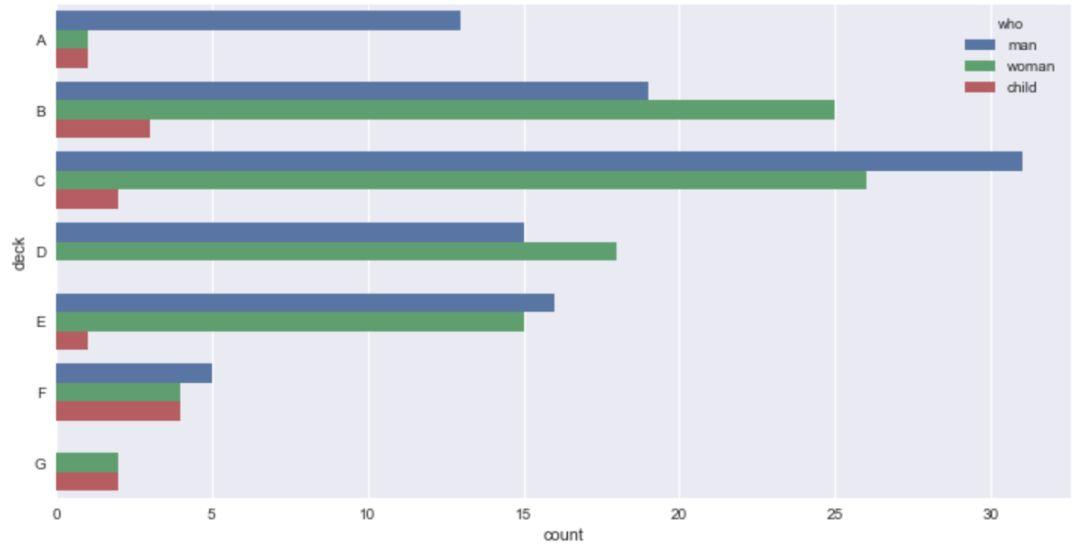
如果我们希望调换横纵坐标,也就是类别放于纵坐标,计数值横坐标显示,将x轴换为y轴即可。
sns.countplot(y='deck',hue='who',data=titanic)
stripplot/swarmplot 散点图¶
在seaborn中有两种不同的分类散点图。stripplot() 使用的方法是用少量的随机“抖动”调整分类轴上的点的位置,swarmplot() 表示的是带分布属性的散点图。
sns.stripplot(x='embarked',y='fare',data=titanic)
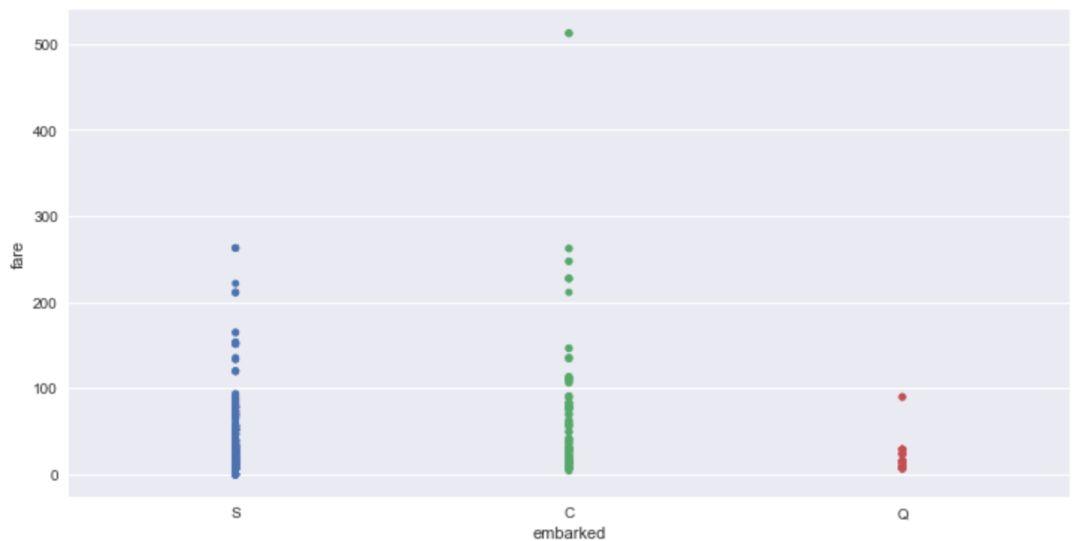
这里我们可以通过设置'jitter'参数控制抖动的大小。
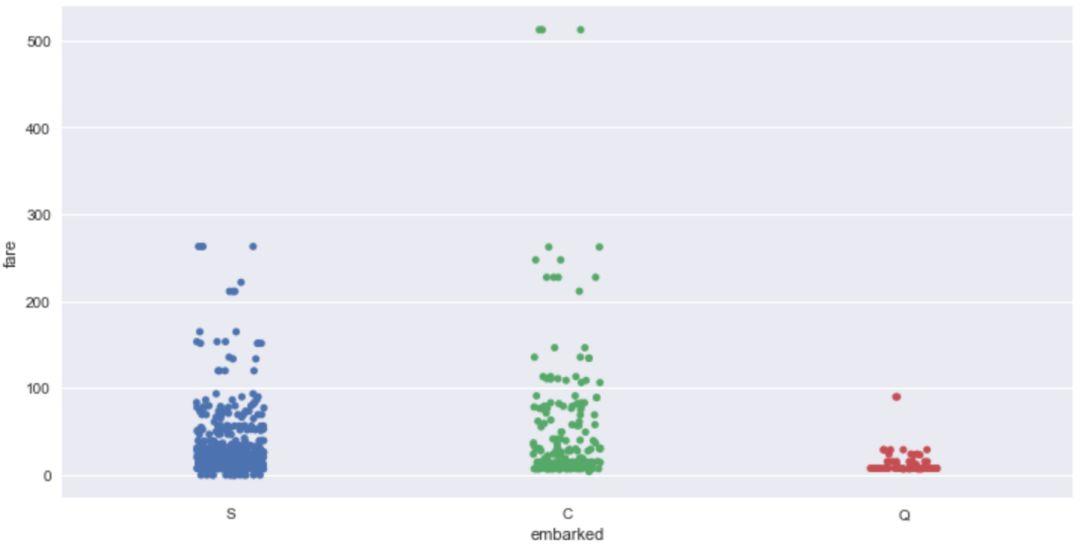
sns.stripplot(x='embarked',y='fare',data=titanic,jitter=1)
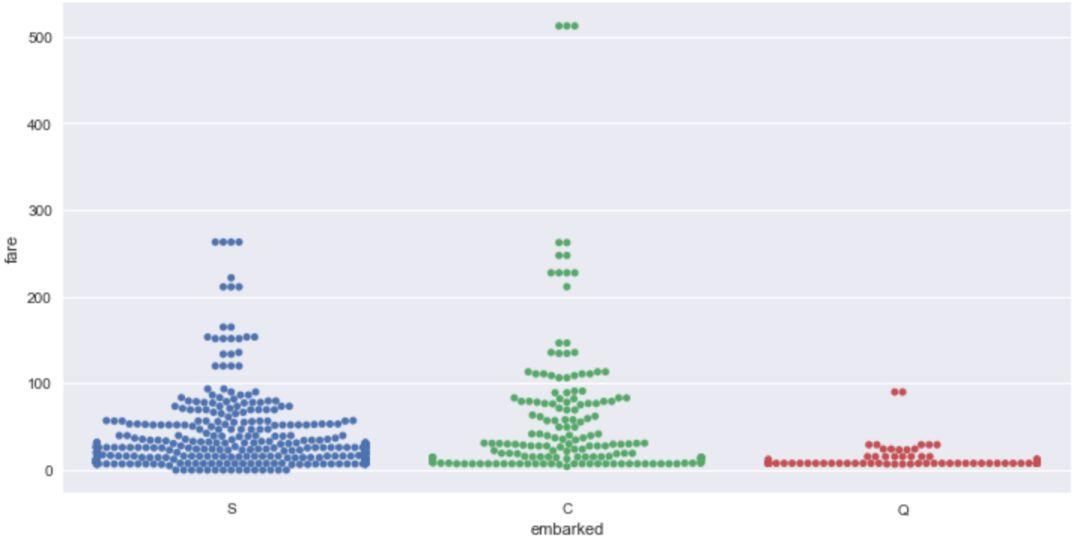
swarmplot() 方法使用防止它们重叠的算法沿着分类轴调整点。它可以更好地表示观测的分布,它适用于相对较小的数据集。
sns.swarmplot(x='embarked',y='fare',data=titanic)
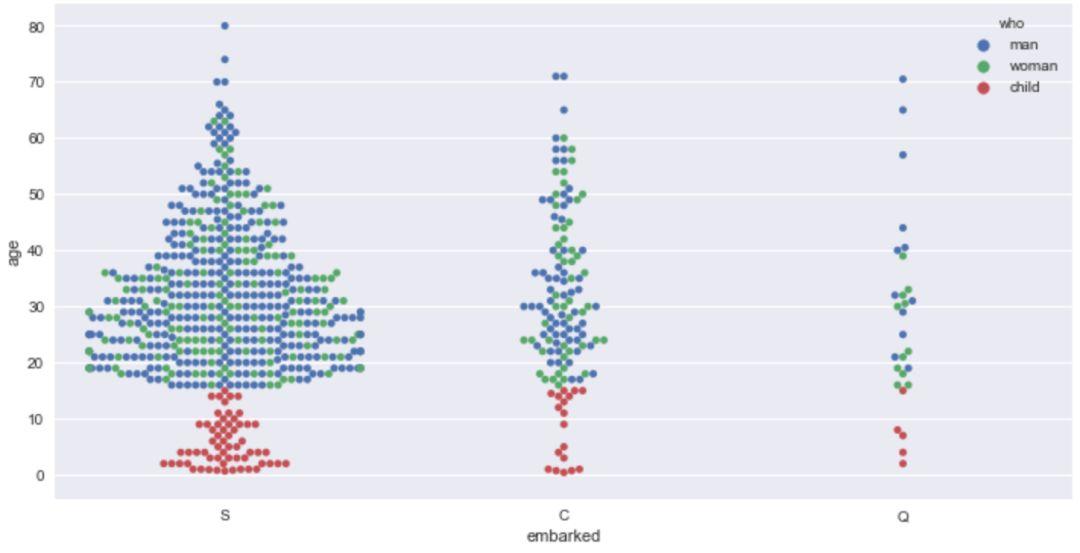
可以通过'hue'参数,对散点图添加更多细分的维度,Seaborn 中会以颜色来进行区分。
python
sns.stripplot(x='embarked',y='age',hue='who',jitter=1,data=titanic)

sns.swarmplot(x='embarked',y='age',hue='who',data=titanic)
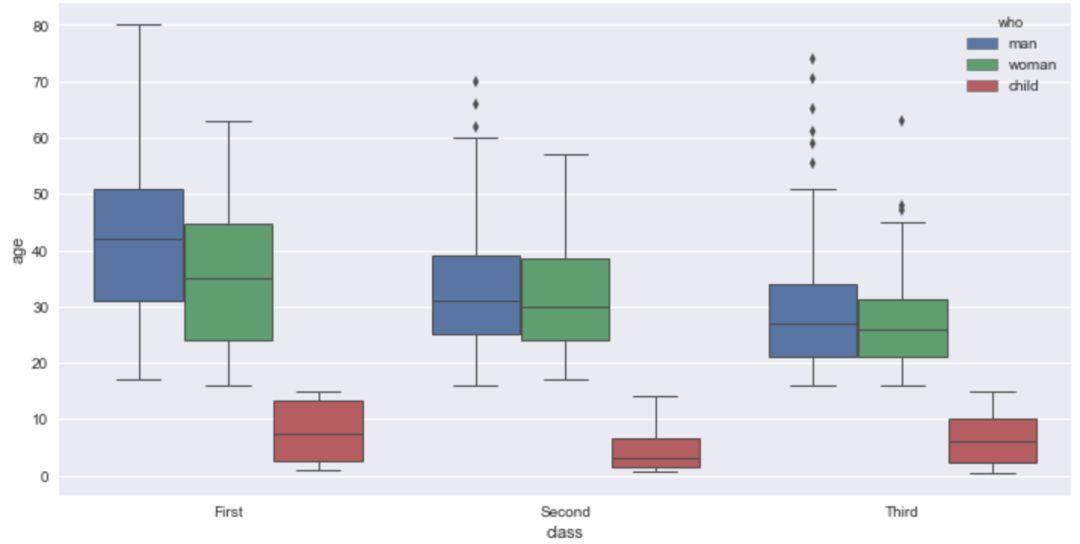
boxplot 箱线图¶
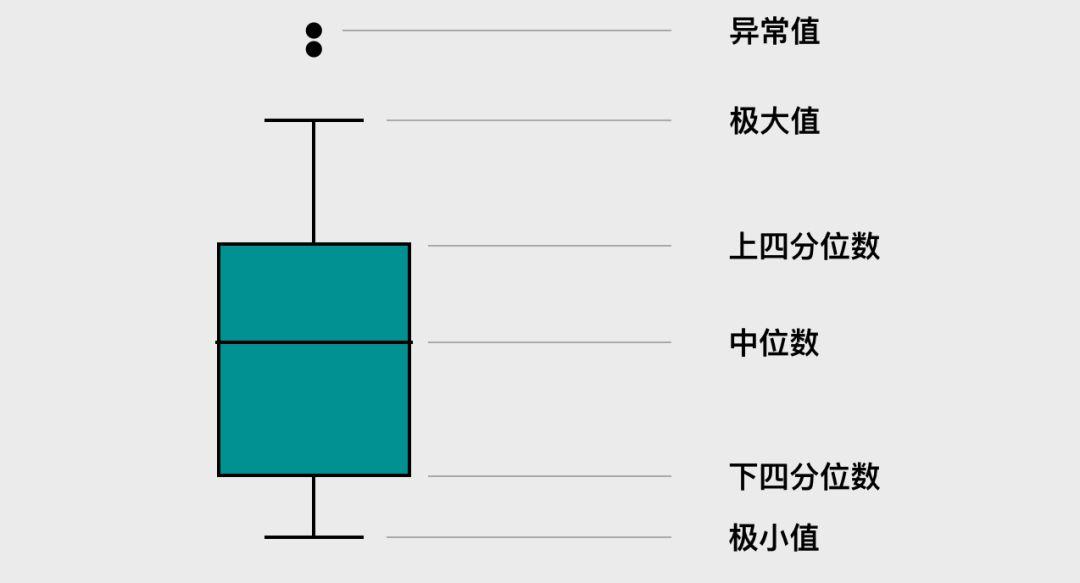
boxplot(箱线图)是一种用作显示一组数据分散情况的统计图。它能显示出一组数据的最大值、最小值、中位数及上下四分位数。因形状如箱子而得名。这意味着箱线图中的每个值对应于数据中的实际观察值。
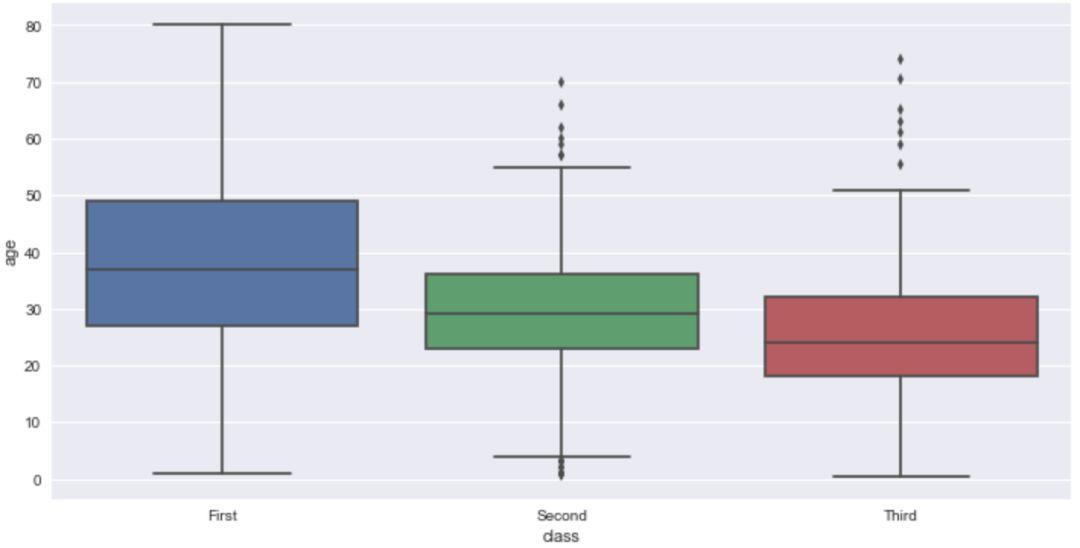
以'titanic'数据集为例,我们首先来探索不同的'class'(船舱)下的乘客的'age'(年龄)情况。
sns.boxplot(x='class',y='age',data=titanic)
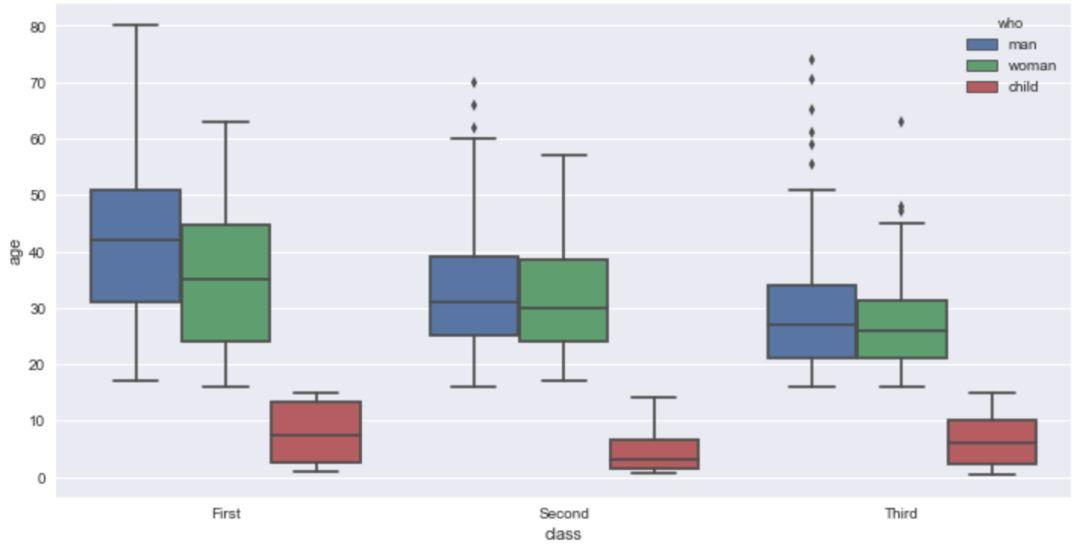
同样的,可以通过传入'hue'的参数,来对x轴的字段进行细分,这里我们通过'who'来进行分类观察。
sns.boxplot(x='class',y='age',hue='who',data=titanic)
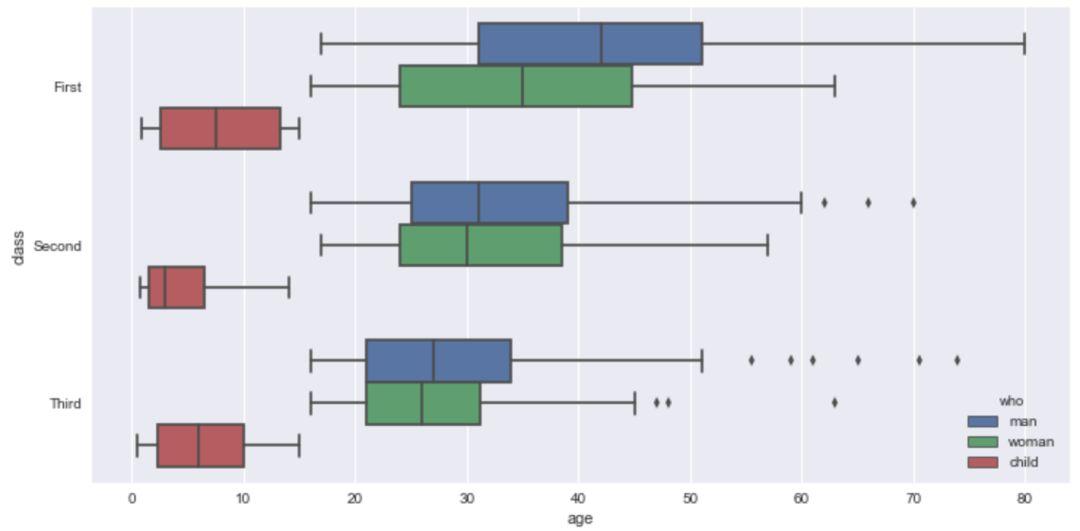
与上述类似,我们也可以通过调换x/y轴,实现箱线图的横向显示。
sns.boxplot(x='age',y='class',hue='who',data=titanic)
调节'order' 和 hue_order 参数,我们可以控制x轴展示的顺序。
fig,axes=plt.subplots(1,2)
sns.boxplot(x='class',y='age',hue='who',
data=titanic,ax=axes[0])
sns.boxplot(x='class',y='age',hue='who',data=titanic,
order=['Third','Second','First'],
hue_order=['child','woman','man'],ax=axes[1])
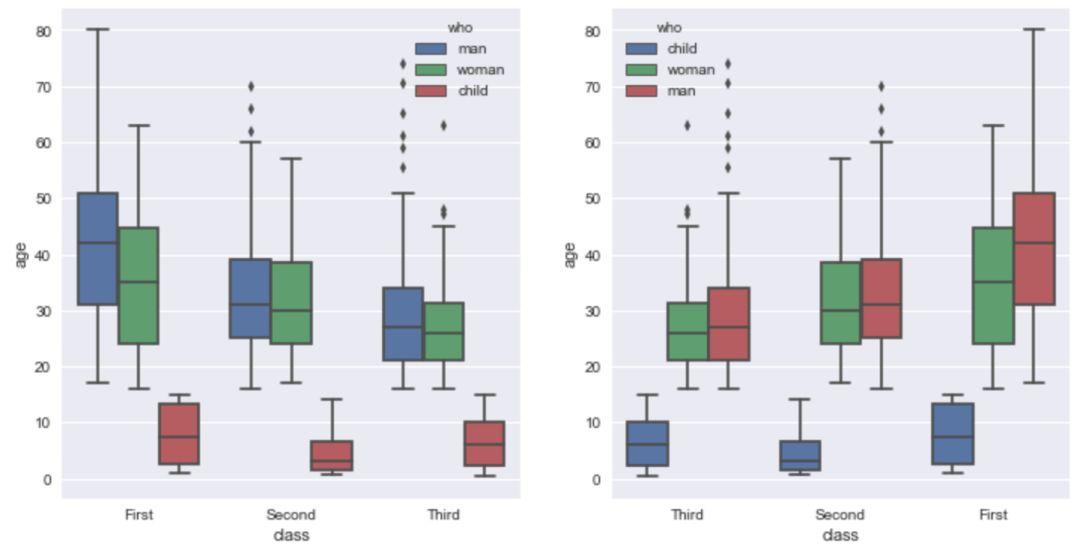
可以通过'linewidth'参数,控制线条的粗细。我们把'linewidth'参数设为1,就可以看到整体图形的线条变细,你可以根据自己的需要调节。
sns.boxplot(x='class',y='age',hue='who', linewidth=1,data=titanic)
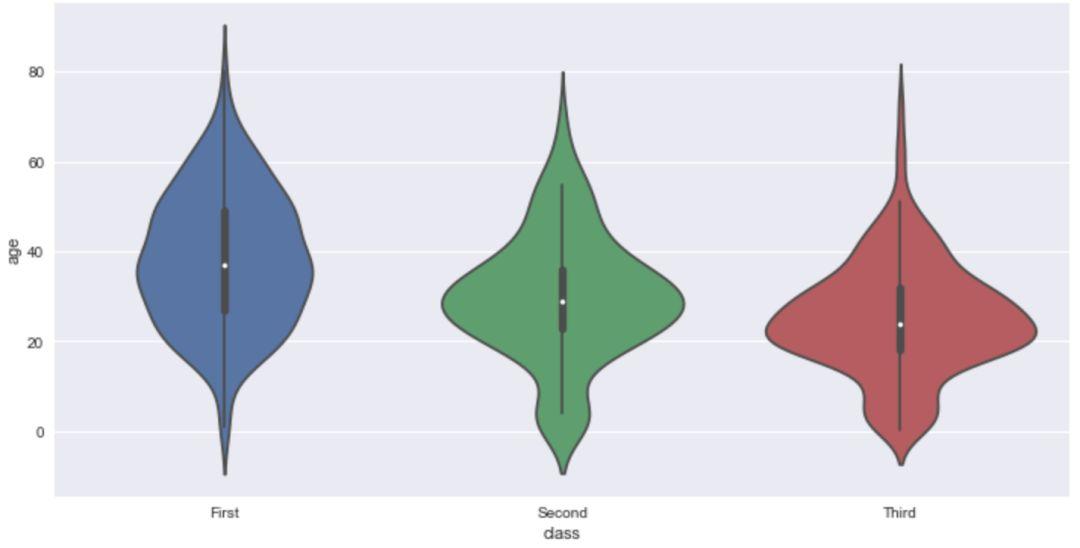
violinplot 小提琴图¶
小提琴图其实是箱线图与核密度图的结合,箱线图展示了分位数的位置,小提琴图则展示了任意位置的密度,通过小提琴图可以知道哪些位置的密度较高。
在图中,白点是中位数,黑色盒型的范围是下四分位点到上四分位点,细黑线表示须。外部形状即为核密度估计。
与箱线图进行对比,同样以'titanic'数据集为例,我们来探索不同的'class'(船舱)下乘客的'age'(年龄)情况。
sns.violinplot(x='class',y='age',data=titanic)
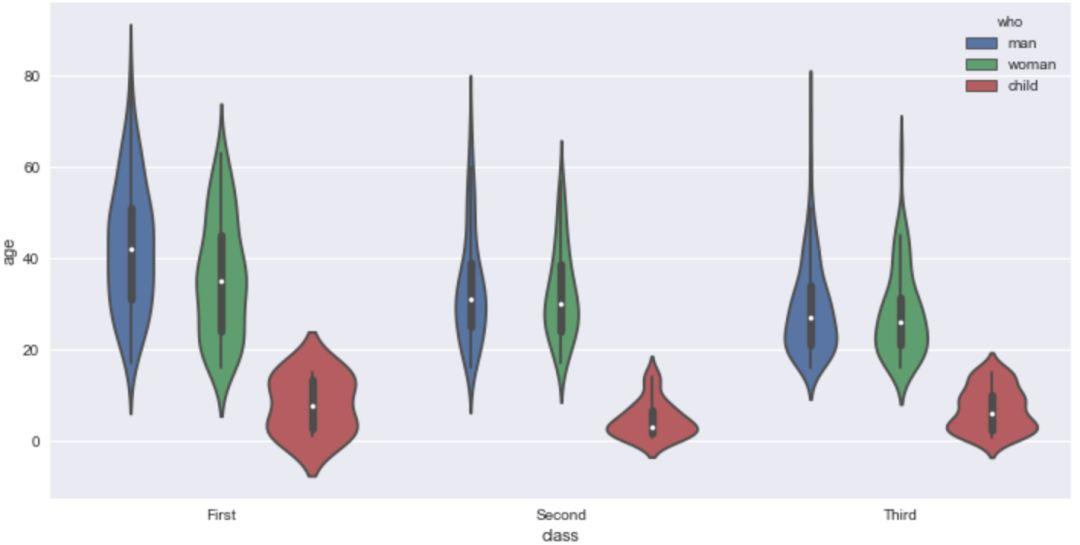
同样,可以设置'hue'参数,对字段进行细分。
sns.violinplot(x='class',y='age',hue='who',data=titanic)
当hue参数只有两个级别时,也可以通过设置'split'参数为True,“拆分”小提琴,提琴两边分别表示两个分类的情况,这样可以更有效地利用空间。
sns.violinplot(x='class',y='age',hue='alive',data=titanic,split=True)
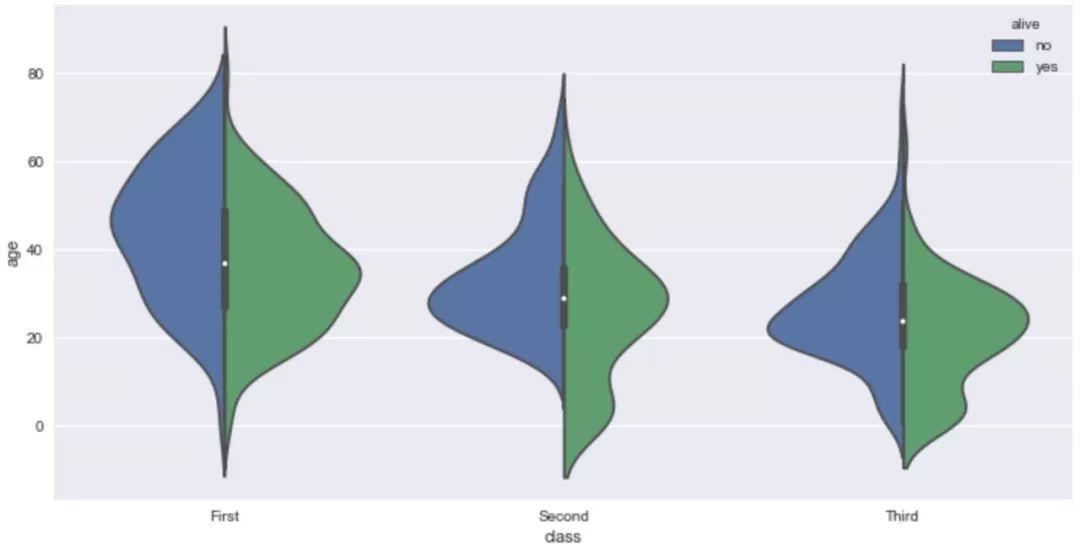
我们可以在小提琴内部添加图形来帮助我们进行分析,这里就需要控制'inner'参数。
sns.violinplot(x='class',y='age',hue='alive',data=titanic,split=True,inner='stick')
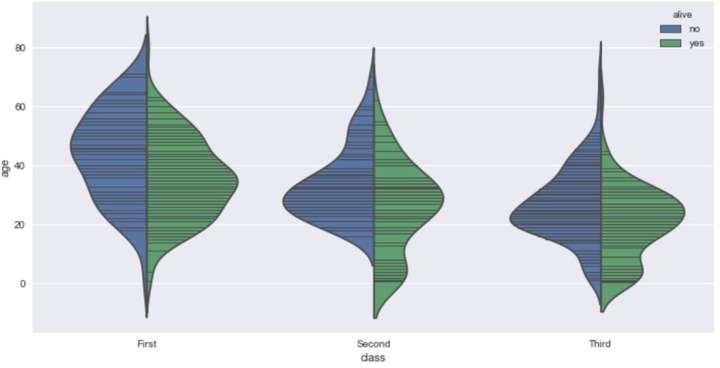
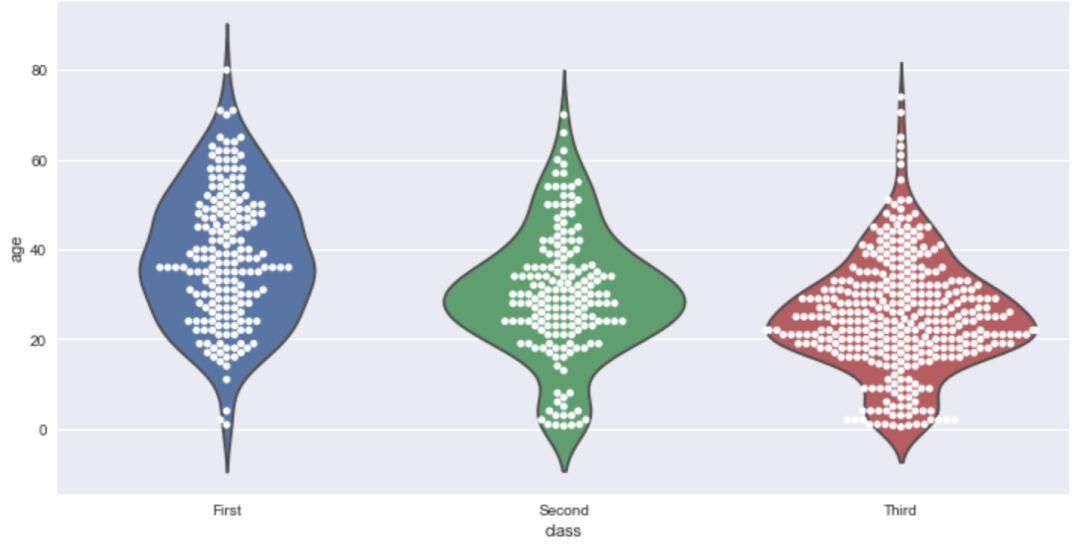
我们甚至可以把上面提到的散点图加入小提琴图中。
sns.violinplot(x='class',y='age',data=titanic,inner=None)
sns.swarmplot(x='class',y='age',data=titanic,color='white')
regplot/lmplot 回归图¶
Seaborn 中利用 regplot() 和 lmplot() 来进行回归,确定线性关系,它们密切相关,共享核心功能,但也有明显的不同。
这里我们使用 Seaborn 自带的数据集'iris'来绘制回归相关的图形。首先我们导入收据来看看数据集的大概情况:
#导入数据集'iris'
iris=sns.load_dataset('iris')
#随机查看数据集的10行数据
iris.sample(10)
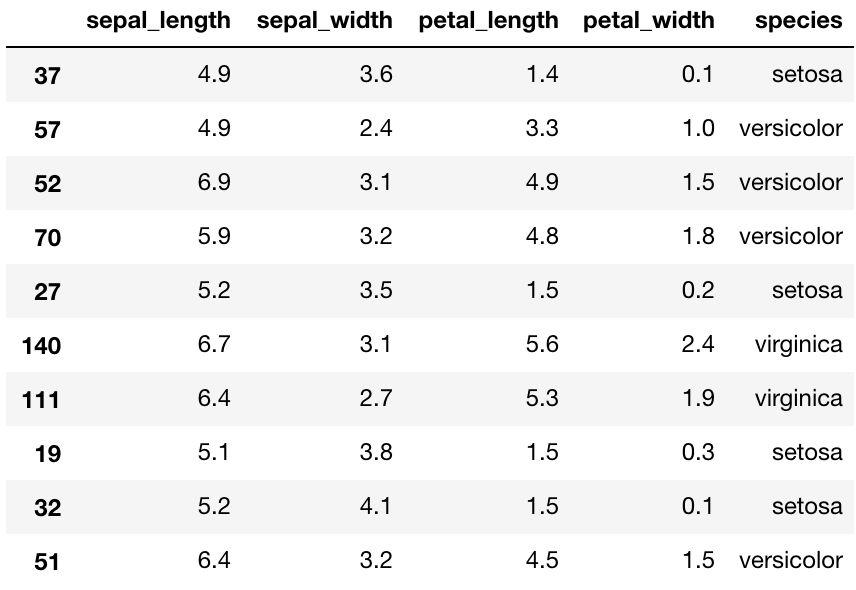
数据集非常简单,总共是5个字段,我们首先来看 sepal_length 和 petal_length 之间的线性关系。
sns.regplot(x='sepal_length',y='petal_length',data=iris)
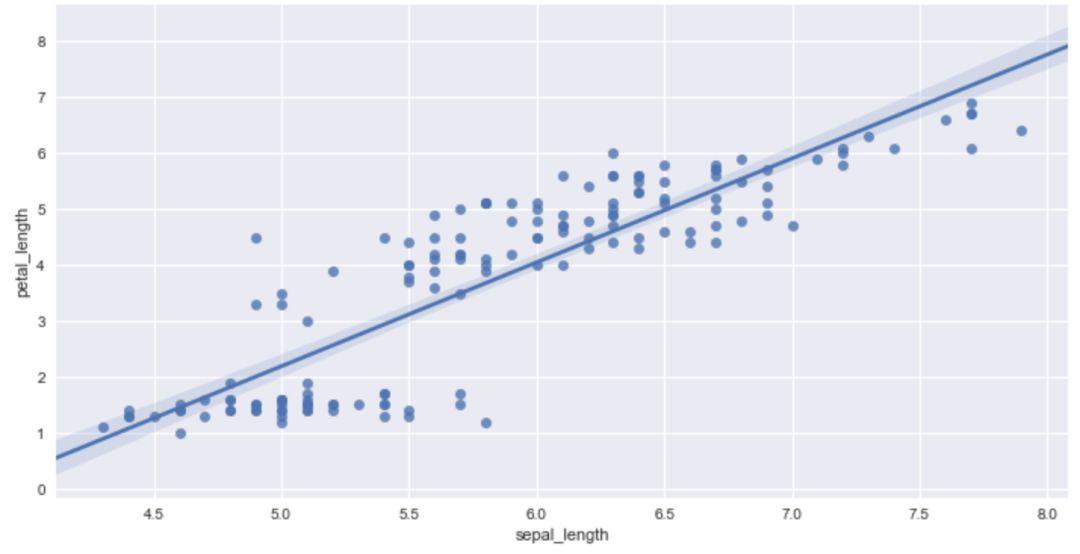
图中的点表示实际的数据点,Seaborn 根据这些数据拟合出直线,表示x轴和y轴对应字段之间的线性关系,直线周围的阴影表示置信区间。
关于置信区间,可以通过设置'ci'参数控制是否显示。
sns.regplot(x='sepal_length',y='petal_length',data=iris,ci=None)
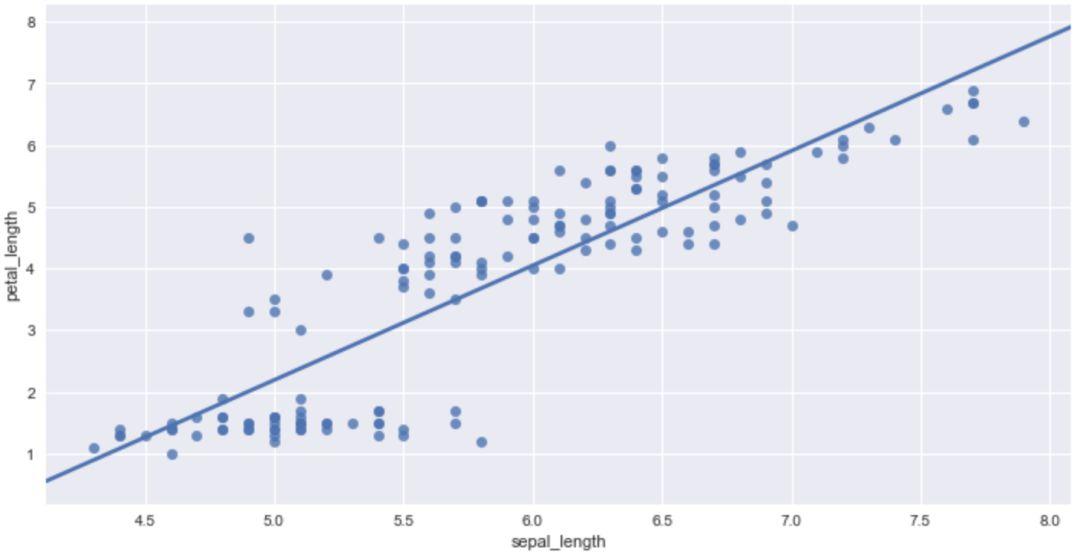
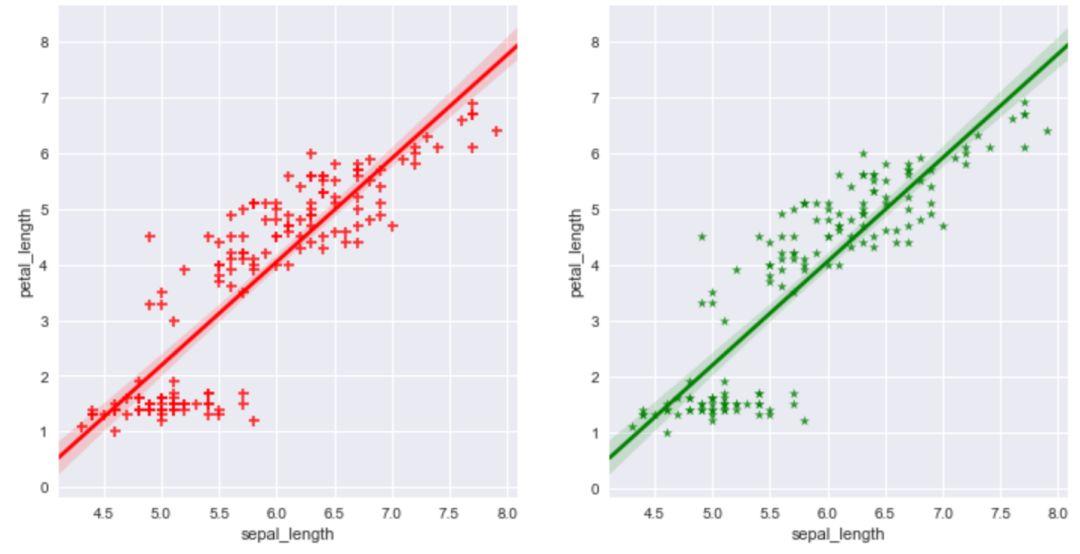
可以通过'color'和'marker'参数来控制图形的颜色以及数据点的形状。
fig,axes=plt.subplots(1,2)
sns.regplot(x='sepal_length',y='petal_length',data=iris,
color='r',marker='+',ax=axes[0])
sns.regplot(x='sepal_length',y='petal_length',data=iris,
color='g',marker='*',ax=axes[1])
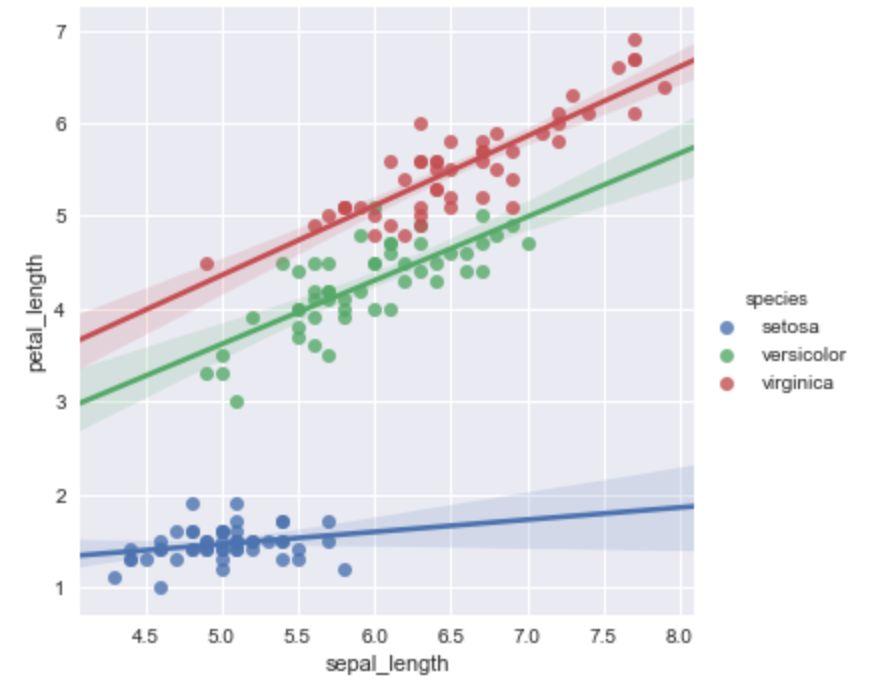
lmplot() 可以设置hue,进行多个类别的显示,而 regplot() 是不支持的。这里我们通过设置 hue='species',来进行分类别地展示。
sns.lmplot(x='sepal_length',y='petal_length', hue='species',data=iris)
同样的,我们也可以更改数据点的形状,来进行区分。
sns.lmplot(x='sepal_length',y='petal_length',hue='species', data=iris,markers=['*','o','+'])
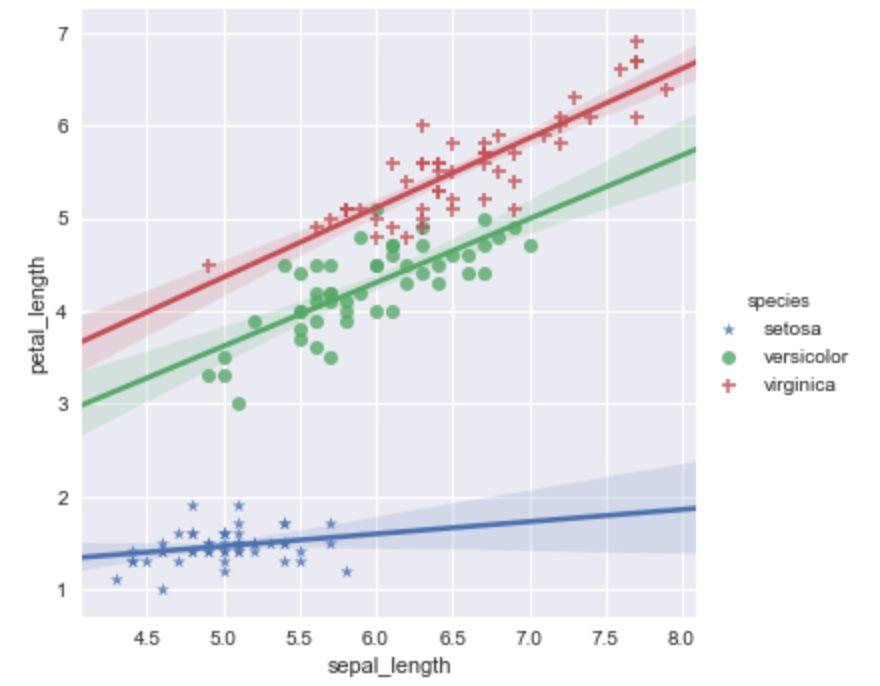
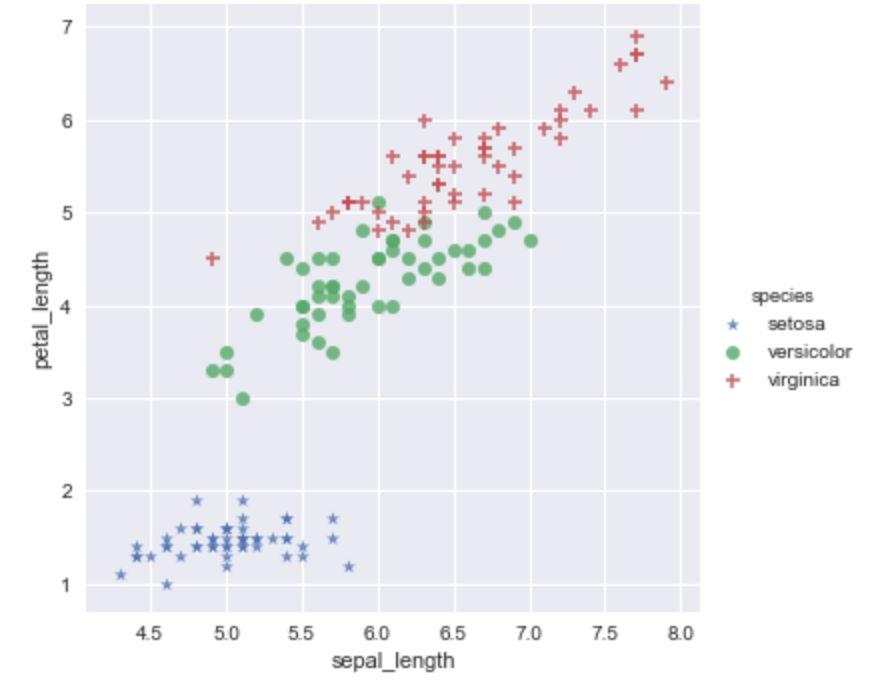
设置 fit_reg 参数,可以控制是否显示拟合的直线。
sns.lmplot(x='sepal_length',y='petal_length',hue='species',
data=iris,markers=['*','o','+'],fit_reg=False)
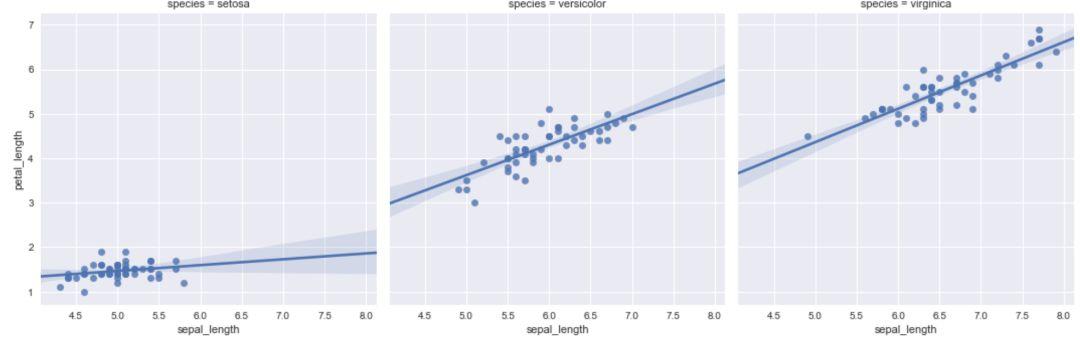
如果要对不同的类别分开绘制,用'col'参数代替'hue'。
sns.lmplot(x='sepal_length',y='petal_length',
col='species',data=iris)
heatmap 热力图¶
热力图通常用来表示特征之间的相关性,一般通过颜色的深浅来表示数值的大小或者相关性的高低。
这里我们导入 Seaborn 自带的另一个数据集'flights',来绘制热力图。先查看数据前10行的情况:
flights = sns.load_dataset("flights")
flights.head(10)
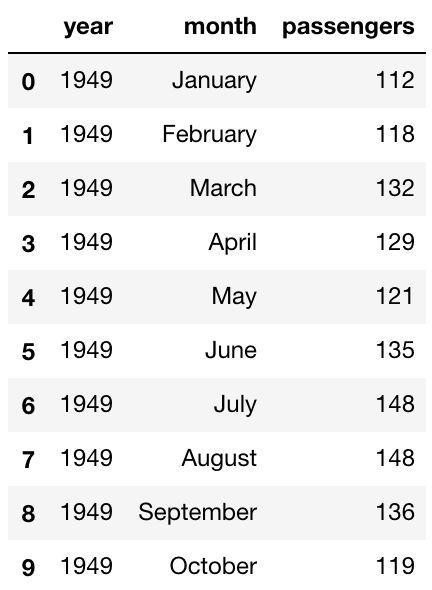
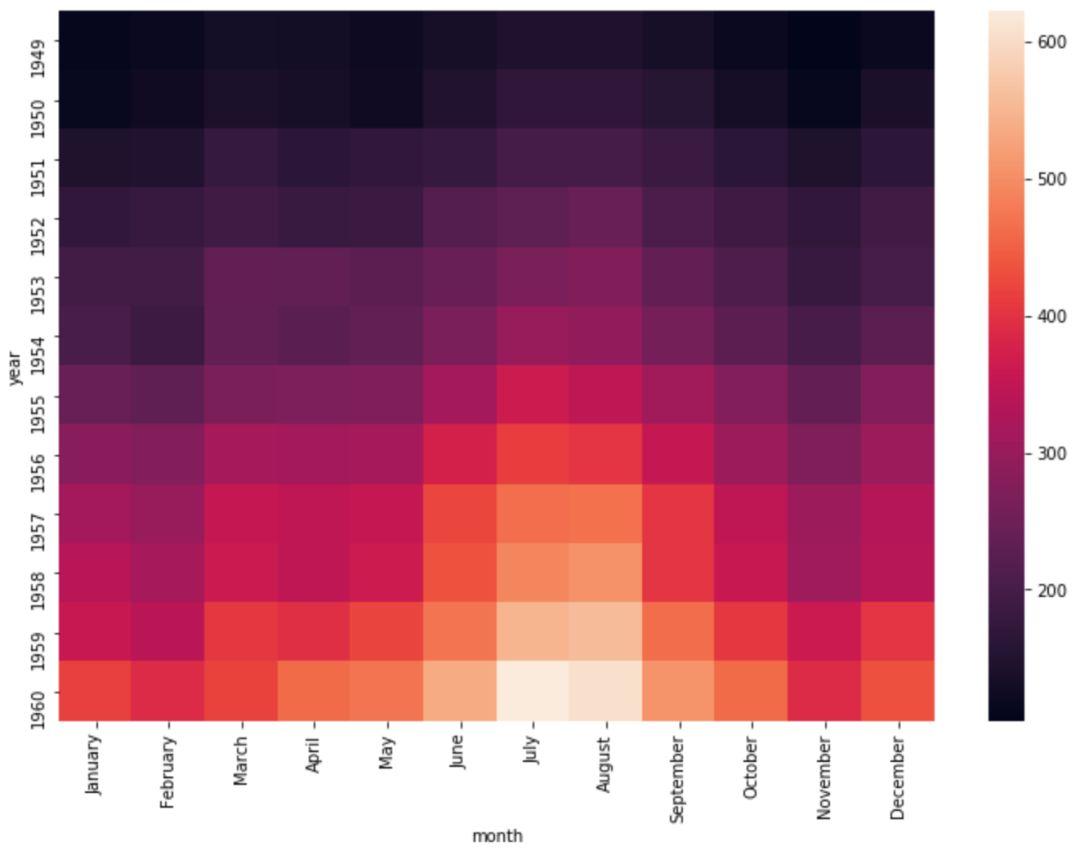
我们以'year'为纵轴,'month'为横轴,'passengers'的值为标准绘制热力图。
f=flights.pivot('year','month','passengers')
sns.heatmap(f)
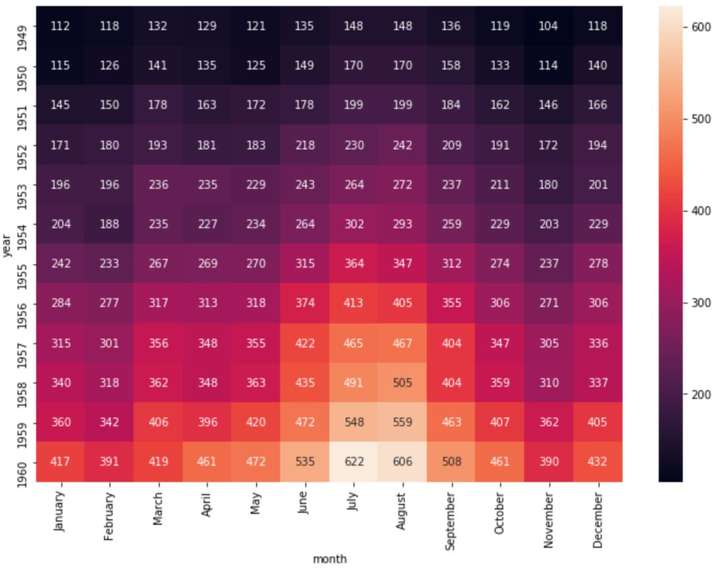
如果要显示具体的数值,可以通过'annot'参数来控制。
sns.heatmap(f, annot=True,fmt="d")
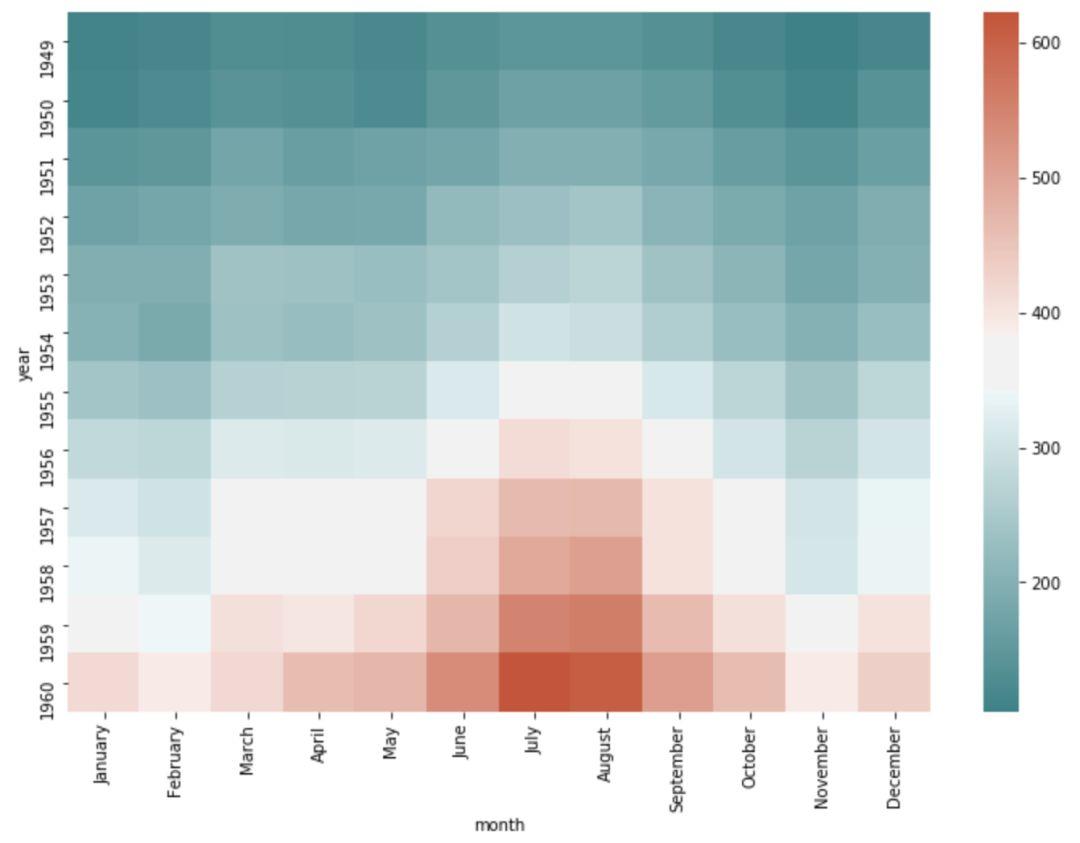
通过 Seaborn 的调色板控制热力图显示的颜色,调色板在后续会有详细的说明,这里只做演示,示例热力图的颜色调节机制。
cmap = sns.diverging_palette(200,20,sep=20,as_cmap=True)
sns.heatmap(f,cmap=cmap)
图形控制的艺术¶
前面我们利用 Seaborn 绘制了各种类型的图形,对于基本的快速分析,其实已经足够,但是在细节的调节、颜色、美观度等方面我们还可以进行精细化的控制。
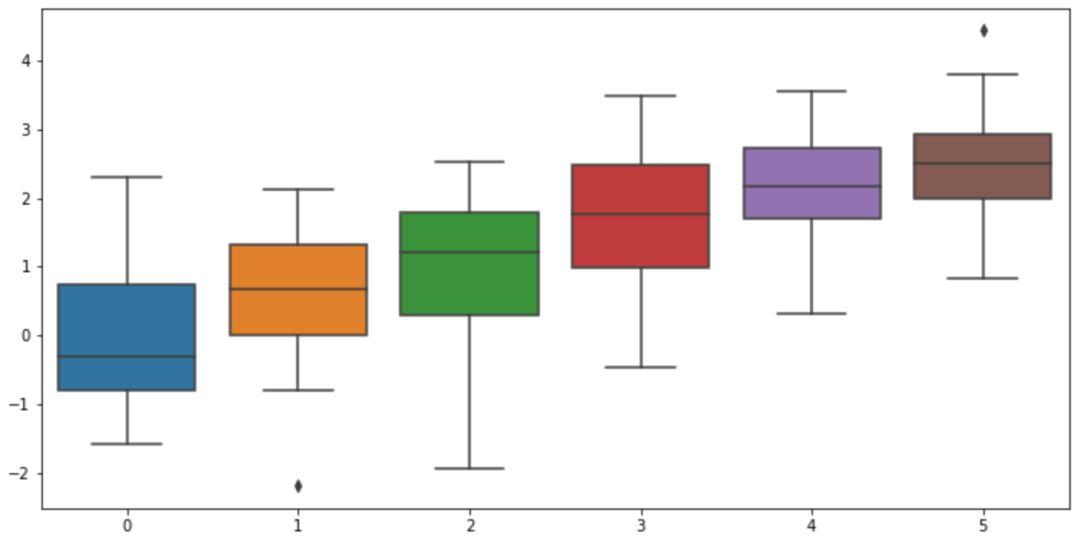
首先我们利用 Numpy 创建一组数据(20行6列的随机数),然后利用 Seaborn 创建一个箱线图来进行展示。
#创建一个20行6列的数据
data = np.random.normal(size=(20, 6)) + np.arange(6) / 2
sns.boxplot(data=data)
图形背景¶
Seaborn 中有 white / whitegrid / dark / darkgrid / ticks 几种样式,用 set_style() 函数控制,分别如下:
-
whitegrid 白色网格背景
-
white 白色背景(默认)
-
darkgrid 黑色网格背景
-
dark 黑色背景
ticks 四周带有刻度的白色背景
# 设为白色网格背景
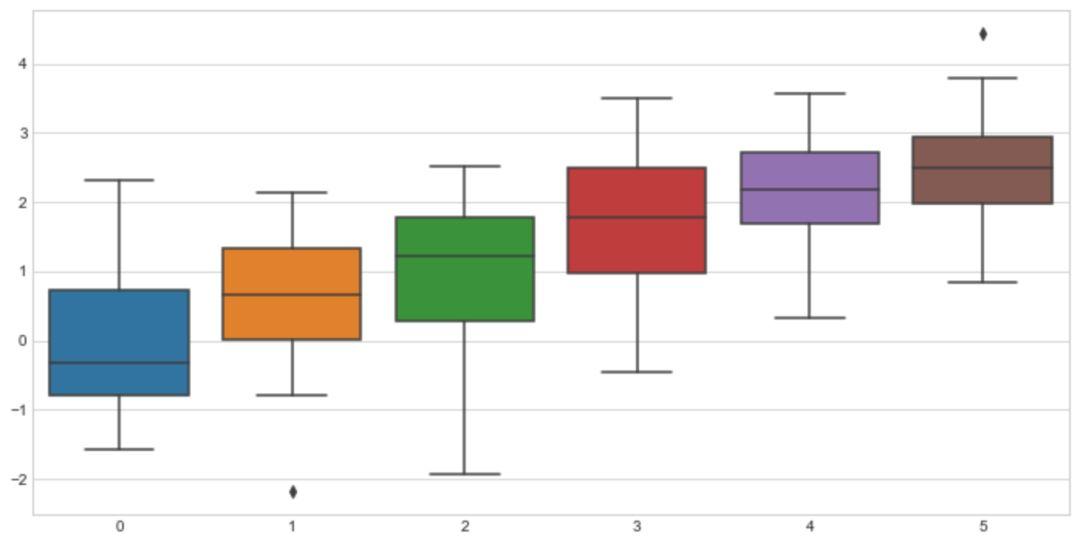
sns.set_style("whitegrid")
sns.boxplot(data=data)
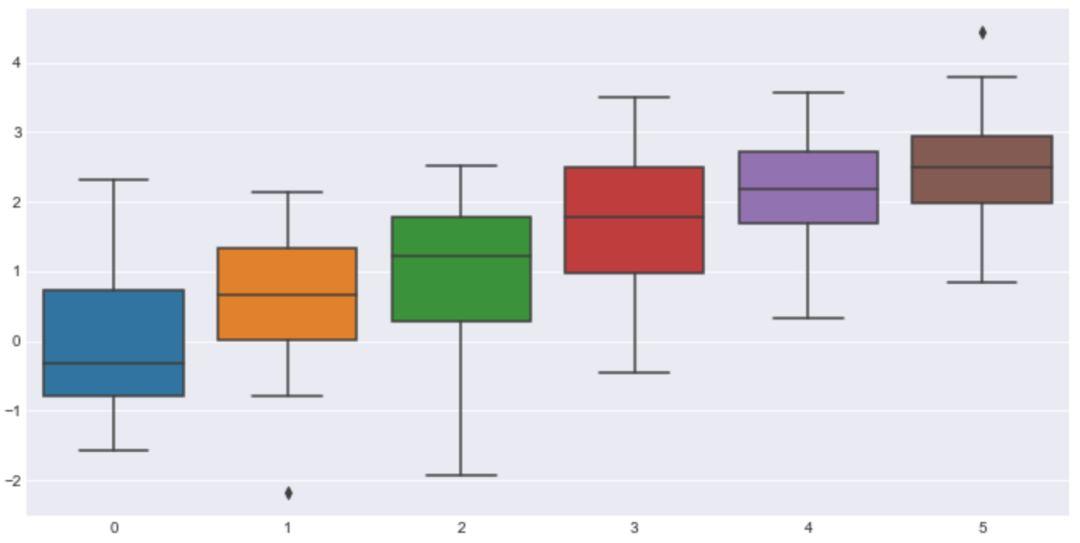
# 设为黑色网格背景
sns.set_style("darkgrid")
sns.boxplot(data=data)
调色板¶
seaborn 中的分类色板,主要用 color_palette() 函数控制,color_palette() 不写参数则显示为 Seaborn 默认颜色。如果需要设置所有图形的颜色,则用 set_palette() 函数定义。
Seaborn 中6个默认的颜色循环主题分别为: deep, muted, pastel, bright, dark, colorblind,下面我们列举演示。
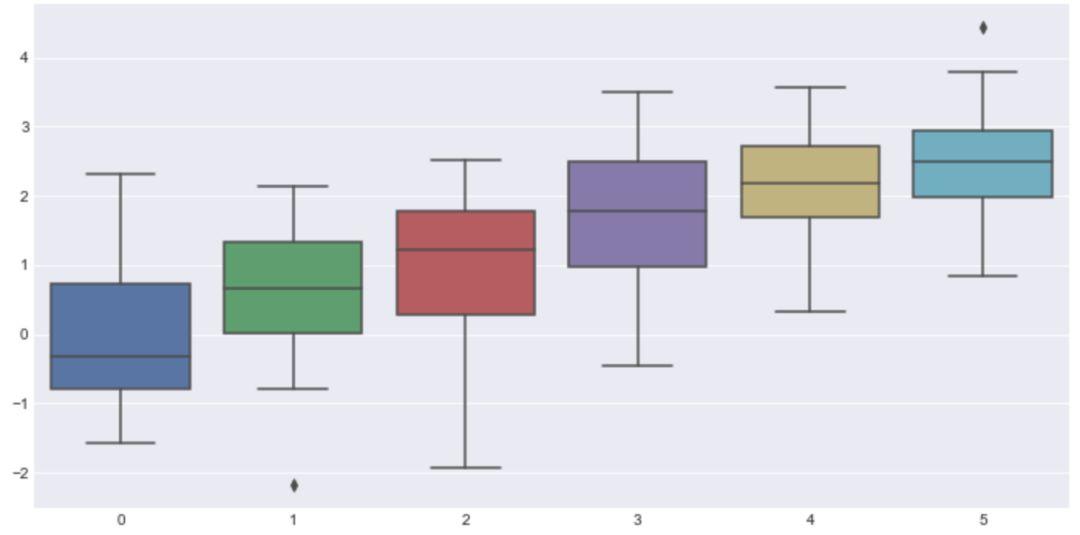
# 设置颜色模式为'deep'
sns.boxplot(data=data,palette=sns.color_palette('deep'))
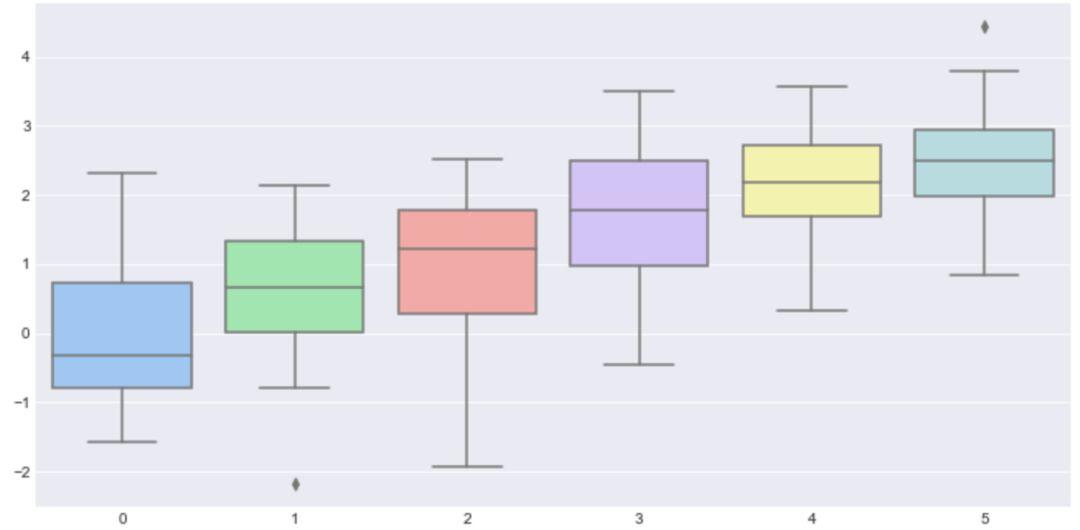
# 设置颜色模式为'pastel'
sns.boxplot(data=data,palette=sns.color_palette('pastel'))
需要注意的是,除了默认的颜色模式有10中颜色外,其他的颜色模式只有6种颜色,如果需要更多颜色,那么则需要采用hls色彩空间。
#创建一个20行10列的数据'data2'
data2 = np.random.normal(size=(20, 10)) + np.arange(10) / 2
#利用hls色彩空间进行调色
sns.boxplot(data=data2, palette=sns.color_palette('hls', 10))
我们也可以通过简单的设置,得到单色渐变的效果,默认颜色由浅到深。
#可以尝试 Reds/Greens,默认颜色由浅到深
sns.boxplot(data=data,palette=sns.color_palette('Blues'))
显示中文¶
Seaborn 对中文的显示不太友好,如果在遇到乱码问题时,可以加入下面的代码。
# 指定默认字体
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像是负号'-'显示为方块的问题
mpl.rcParams['axes.unicode_minus'] = False
保存图片¶
画出的图形我们需要保存,可以先建立一个画布,设置我们图像的大小,然后将这个画布保存下来。
#设置一个(12,6)的画布
plt.figure(figsize=(12, 6))
#图形绘制代码
sns.boxplot(data=data,palette=sns.color_palette('Blues'))
#将画布保存为'xiang.png',还可以保存为jpg、svg格式图片
plt.savefig('xiang.png')